Drzewo splay
 | Ten artykuł od 2014-06 zawiera treści, przy których brakuje odnośników do źródeł. Należy dodać przypisy do treści niemających odnośników do źródeł. Dodanie listy źródeł bibliograficznych jest problematyczne, ponieważ nie wiadomo, które treści one uźródławiają. Sprawdź w źródłach: Encyklopedia PWN • Google Books • Google Scholar • Federacja Bibliotek Cyfrowych • BazHum • BazTech • RCIN • Internet Archive (texts / inlibrary) Dokładniejsze informacje o tym, co należy poprawić, być może znajdują się w dyskusji tego artykułu. Po wyeliminowaniu niedoskonałości należy usunąć szablon {{Dopracować}} z tego artykułu. |
Drzewo splay (drzewo rozchylane, drzewo Sleatora-Tarjana[1]) – struktura danych w formie samodostosowującego się drzewa poszukiwań binarnych (BST), wynaleziona przez Daniela Sleatora i Roberta Tarjana, reprezentująca zbiór elementów z porządkiem liniowym.
Wykonywanie podstawowych operacji na drzewie splay wiąże się z wykonaniem procedury która powoduje taką zmianę struktury drzewa że węzeł zostaje umieszczony w korzeniu przy zachowaniu porządku charakterystycznego dla drzewa BST.



W porównaniu do innych drzew BST, drzewa splay zmieniają swoją strukturę również podczas wyszukiwana kluczy (a nie tylko dodawania lub usuwania), przesuwając znaleziony węzeł w kierunku korzenia, dzięki temu często wyszukiwane węzły stają się szybsze do znalezienia. Z tego powodu drzewa splay bywają wykorzystywane w systemach typu cache. Drzewa splay nie są samorównoważące, ponieważ ich wysokość nie jest ograniczona przez – można np. tak wykonać operacje, że drzewo zdegeneruje się do listy.

Podstawowe operacje na drzewie splay, tj. wyszukiwanie elementu oraz wstawianie i usuwanie, są wykonywane w zamortyzowanym czasie gdzie jest liczbą elementów w drzewie[2]. Oznacza to, że dla dowolnego ciągu operacji na drzewie splay, łączny koszt wykonania tych operacji jest rzędu




Operacja Splay
Operacja Splay jest procedurą kluczową dla działania drzewa typu splay. Polega ona na wykonaniu sekwencji kroków, z których każdy przybliża element do korzenia. Każdy krok polega na wykonaniu jednej lub dwóch rotacji względem krawędzi wchodzących w skład początkowej ścieżki od do korzenia.
W każdym kroku procedury niech oznacza ojca węzła a jeśli nie jest korzeniem, niech oznacza z kolei jego ojca (i dziadka ). Wyróżniamy trzy przypadki kroków procedury Splay, w zależności od tego czy jest korzeniem i od wzajemnego położenia węzłów i [2]:




Krok zig
Wykonywany kiedy jest korzeniem, polega na rotacji drzewa względem krawędzi Ten krok może być wykonany tylko jako ostatni krok procedury Splay.


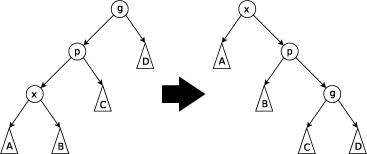
Krok zig-zig
Wykonywany kiedy nie jest korzeniem, a i są krawędziami w jedną stronę, tj. jest lewym synem który jest lewym synem albo jest prawym synem a – prawym synem Polega na rotacji względem krawędzi łączącej ojca i dziadka wierzchołka a potem względem krawędzi łączącej z jego ojcem.





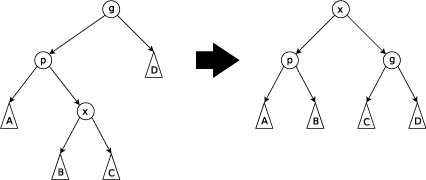
Krok zag-zig
Wykonywany kiedy nie jest korzeniem, oraz jest lewym synem a – prawym synem lub odwrotnie. W tym kroku najpierw wykonuje się rotację względem krawędzi a następnie względem krawędzi która powstaje w wyniku pierwszej rotacji.


Implementacje podstawowych operacji
W opisie implementacji operacji na drzewie splay będziemy utożsamiali wierzchołek z przechowywaną w nim wartością.
Wyszukiwanie
Wyszukiwanie wierzchołka zawierającego daną wartość odbywa się jak w drzewie BST, przy czym jeżeli wyszukiwanie zakończyło się powodzeniem, a szukana wartość znajduje się w węźle to wywołujemy W przeciwnym wypadku wykonujemy gdzie jest ostatnim węzłem drzewa odwiedzonym przy wyszukiwaniu.



Wstawienie
Aby wstawić do drzewa wartość wyszukujemy w jak powyżej, wskutek czego w korzeniu znajduje się wartość Jeżeli to wstawienie jest zakończone, ponieważ oznacza to, że przed wstawieniem w już znajdowało się W przeciwnym wypadku przyjmijmy, że (sytuacja odwrotna jest symetryczna). Odcinamy od jego prawe poddrzewo i tworzymy nowy węzeł zawierający którego lewym synem czynimy a prawym – korzeń poddrzewa [3].







Usuwanie
Aby usunąć z drzewa wartość wyszukujemy jak powyżej. Teraz znajduje się w korzeniu i ma poddrzewa: lewe i prawe Usuwamy wierzchołek a następnie wyszukujemy w wartości co powoduje przemieszczenie do korzenia największej wartości w poddrzewie Do korzenia podłączamy jako prawe poddrzewo[3].



Inne operacje
W drzewach splay szczególnie łatwo jest zaimplementować operacje split – dzielenia drzewa na dwa drzewa i tak, że wszystkie elementy w są mniejsze, a w – większe od zadanej wartości oraz join – połączenia dwóch drzew i takich, że każdy element w jest mniejszy niż każdy element w



wyszukaj w element zgodnie z algorytmem podanym powyżej, następnie w zależności od tego, czy w korzeniu jest obecnie wartość większa czy mniejsza od dzielimy drzewo, usuwając krawędź z korzenia do lewego bądź prawego syna.

W wyszukujemy dowolny element z w wyniku czego w korzeniu pojawia się wierzchołek z największą wartością z który nie ma prawego syna. Jako jego prawego syna podłączamy korzeń drzewa





Zalety i wady drzew splay
Drzewo splay charakteryzuje się asymptotycznie takim samym średnim kosztem dostępu, co samorównoważące się drzewa BST, w tym drzewa AVL oraz drzewa czerwono-czarne. Mimo to, w przypadku jednakowych prawdopodobieństw dostępu do poszczególnych elementów, drzewa splay działają w praktyce (choć nie asymptotycznie) wolniej niż inne tego typu drzewa, które dodatkowo posiadają ograniczenia na pesymistyczny koszt operacji. Zaletą drzew splay jest optymalizowanie dostępu przez przesuwanie wartości, do których ostatnio uzyskiwano dostęp, blisko korzenia, co powoduje ich dużą przydatność w implementacji pamięci cache i algorytmów odśmiecania.
Inną zaletą drzew splay w stosunku do drzew AVL i czerwono-czarnych jest łatwiejsza implementacja oraz niski nakład pamięciowy na przechowywanie drzewa. Sleator i Tarjan w swojej pracy[2] o drzewach typu splay opracowali sposób implementacji drzew splay wymagający takiej samej pamięci, jak standardowa implementacja drzew BST, w której w węźle przechowywane są jedynie: przechowywany element oraz dwa wskaźniki.
W przeciwieństwie do innych wyważonych drzew BST łatwo zaimplementować wariant drzew typu splay, który może przechowywać powtarzające się wartości (reprezentuje multizbiór).
Zobacz też
- binarne drzewo poszukiwań (drzewo BST)
- drzewo AVL
- drzewo czerwono-czarne
Przypisy
- ↑ Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, Clifford Stein ↓, s. 432.
- ↑ a b c D. Sleator, R. Tarjan, Self-Adjusting Binary Search Trees [1].
- ↑ a b K. Diks, A. Malinowski, W. Rytter, T. Waleń, Algorytmy i struktury danych – słowniki, materiały dydaktyczne w serwisie wazniak.mimuw.edu.pl [2].
Bibliografia
- Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, Clifford Stein: Wprowadzenie do algorytmów. WNT, 2007.
Linki zewnętrzne
- Oryginalna praca Sleatora i Tarjana (pdf)
- Wizualizacja drzew splay
- Implementacje w C i Javie autorstwa Daniela Sleatora.











