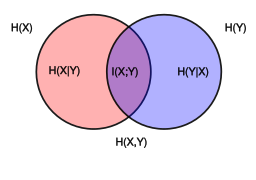
Vennův diagram ukazující aditivní a subtraktivní vztahy různých informačních měr přiřazených ke korelovaným proměnným a . Plocha pokrytá některou z kružnic je sdružená entropie . Kružnice vlevo (červená a fialová) je entropie, přičemž červená je podmíněná entropie . Kružnice vpravo (modrá a fialová) je , přičemž modrá je . Fialová je vzájemná informace.
Podmíněná entropie (anglicky conditional entropy) v teorii informace kvantifikuje množství informace potřebné pro popsání výsledku náhodného pokusu, pokud je známá hodnota jiné náhodné proměnné . Měří se stejně jako informační entropie v bitech (kterým se v této souvislosti také říká „shannons“), někdy v „přirozených jednotkách“ (natech) nebo v desítkových číslicích (nazývaný „dits“, „bans“ nebo „hartleys“). Jednotka měření závisí na základu logaritmu použitého pro výpočet entropie.
Entropii podmíněnou zapisujeme , kde je velké řecké písmeno Éta.
Definice
Podmíněná entropie , je-li dáno , je definována jako
Poznámka: při výpočtech se neurčité výrazy a pro pevné považují za rovné nule, protože a .[1]
Intuitivní vysvětlení definice: Podle definice platí, že kde přiřazuje dvojici informační obsah , je-li dáno , což je množství informace potřebné pro popsání události , je-li dáno . Podle zákona velkýich čísel, je aritmetický průměr velkého počtu nezávislých realizací .
Motivace
Nechť je entropie diskrétní náhodné proměnné podmíněná tím, že diskrétní náhodná proměnná nabývá hodnotu . Označme nosiče funkcí a a . Nechť má pravděpodobnostní funkci. Nepodmíněná entropie se spočítá jako , tj.
kde je informační obsah toho, že výsledek má hodnotu . Entropie podmíněná tím, že nabývá hodnotu , je definována podobně podmíněné očekávání:
Pamatujte, že je výsledek průměrování přes všechny možné hodnoty , kterých může nabývat . Také pokud se výše uvedený součet bere přes vzorek , očekávaná hodnota je známa v nějakém oboru jako ekvivokace (anglicky equivocation).[2]
Jsou-li dány diskrétní náhodné proměnné s obrazem a s obrazem , podmíněná entropie , je-li dáno se definuje jako vážený součet pro každou možnou hodnotu , s použitím jako váhy:[3]:s.15
Vlastnosti
Nulová podmíněná entropie
právě tehdy, když hodnota je úplně určena hodnotou .
Podmíněná entropie of nezávislý náhodné proměnné
Naopak právě tehdy, když a jsou nezávislé náhodné proměnné.
Řetízkové pravidlo
Předpokládejme, že kombinovaný systém určený dvěma náhodnými proměnnými a má sdruženou entropii , tj. potřebujeme průměrně bitů informace pro popsání jeho přesného stavu. Pokud nejdříve zjistíme hodnotu , získali jsme bitů informace. Pokud je známé, potřebujeme pouze bitů pro popsání stavu celého systému. Tato hodnota se přesně rovná , kterou dává řetízkové pravidlo podmíněné entropie:
[3]:s.17
řetízkové pravidlo vyplývá z výše uvedené definice podmíněné entropie:
Řetízkové pravidlo platí obecně pro více náhodné proměnné:
Přestože určitá podmíněná entropie může být menší i větší než pro dané náhodné variace , nemůže nikdy přesáhnout .
Podmíněná diferenciální entropie
Definice
Výše uvedená definice platí pro diskrétní náhodné proměnné. Spojitá verze diskrétní podmíněné entropie se nazývá podmíněná diferenciální (nebo spojitá) entropie. Nechť a jsou spojité náhodné proměnné se sdruženou hustotou pravděpodobnosti. Diferenciální podmíněná entropie se definuje takto[3]:s.249
(2)
Vlastnosti
Oproti podmíněné entropii pro diskrétní náhodné proměnné může být podmíněná diferenciální entropie záporná.
Stejně jako v diskrétním případě platí řetízkové pravidlo pro diferenciální entropii:
[3]:s.253
Toto pravidlo však neplatí, pokud se příslušné diferenciální entropie neexistují nebo jsou nekonečné.
Sdružené diferenciální entropie se také používají v definici vzájemné informace mezi spojitými náhodnými proměnnými:
, přičemž rovnost nastává právě tehdy, když a jsou nezávislé.[3]:s.253
Vztah k chybě odhad
Podmíněné diferenciální entropie dává spodní mez očekávané druhé mocniny chyby odhadu. Pro jakoukoli náhodnou proměnnou , pozorování a odhad platí:[3]:s.255
V kvantové teorii informace se podmíněná entropie zobecňuje na podmíněnou kvantovou entropii, která na rozdíl od svého klasického protějšku může nabývat záporných hodnot.
Odkazy
Reference
V tomto článku byl použit překlad textu z článku Conditional entropy na anglické Wikipedii.
↑David MacKay: Information Theory, Pattern Recognition and Neural Networks: The Book [online]. [cit. 2019-10-25]. Dostupné online.
↑HELLMAN, M.; RAVIV, J. Probability of error, equivocation, and the Chernoff bound. IEEE Transactions on Information Theory. 1970, roč. 16, čís. 4, s. 368–372.
↑ abcdefgCOVER, Thomas M. Elements of Information Theory. [s.l.]: [s.n.], 1991. Dostupné online. ISBN0-471-06259-6.





























![{\displaystyle \mathrm {H} (Y):=\mathbb {E} [\operatorname {I} (Y)]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f114631caeb95e508a74994486e35e972220b378)





![{\displaystyle E_{X}[\mathrm {H} (y_{1},\dots ,y_{n}\mid X=x)]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c42f84b74f174cb4c172b6f91074f65dbd915e40)






![{\displaystyle {\begin{aligned}\mathrm {H} (Y|X)&=\sum _{x\in {\mathcal {X}},y\in {\mathcal {Y}}}p(x,y)\log \left({\frac {p(x)}{p(x,y)}}\right)\\[4pt]&=\sum _{x\in {\mathcal {X}},y\in {\mathcal {Y}}}p(x,y)(\log(p(x))-\log(p(x,y)))\\[4pt]&=-\sum _{x\in {\mathcal {X}},y\in {\mathcal {Y}}}p(x,y)\log(p(x,y))+\sum _{x\in {\mathcal {X}},y\in {\mathcal {Y}}}{p(x,y)\log(p(x))}\\[4pt]&=\mathrm {H} (X,Y)+\sum _{x\in {\mathcal {X}}}p(x)\log(p(x))\\[4pt]&=\mathrm {H} (X,Y)-\mathrm {H} (X).\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/501bd3a915d2218c4464e1ea8cfefc3fba872320)


















![{\displaystyle \mathbb {E} \left[{\bigl (}X-{\widehat {X}}{(Y)}{\bigr )}^{2}\right]\geq {\frac {1}{2\pi e}}e^{2h(X|Y)}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ab916a1ac9b14193bf90b79742772b686bb771c3)









